
Движок загрузки данных
Gato GraphQL использует серверные компоненты для представления модели данных (а не графы или деревья). Рассмотрим, как он выполняет процесс загрузки данных для разрешения GraphQL-запроса.
Чтобы обработать данные, необходимо выровнять компоненты в типы (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), упорядочить их в соответствии с их появлением в иерархии компонентов (Director, затем Film, затем Actor) и обрабатывать их «итерациями», извлекая данные объектов для каждого типа в своей собственной итерации:

Движок загрузки данных сервера должен реализовать следующий (псевдо-)алгоритм для загрузки данных:
Подготовка:
- Подготовить пустую очередь для хранения списка ID объектов, которые должны быть получены из базы данных, организованных по типу (каждая запись будет:
[тип => список ID]) - Получить ID объекта избранного режиссёра и поместить его в очередь под типом
Director
Цикл до тех пор, пока в очереди не останется записей:
- Получить первую запись из очереди: тип и список ID (например:
Directorи[2]), и удалить эту запись из очереди - Используя объект
TypeDataLoaderтипа, выполнить один запрос к базе данных для получения всех объектов этого типа с указанными ID - Если тип имеет реляционные поля (например: тип
Directorимеет реляционное полеfilmsтипаFilm), то собрать все ID из этих полей у всех объектов, полученных в текущей итерации (например: все ID в полеfilmsу всех объектов типаDirector), и поместить эти ID в очередь под соответствующим типом (например: ID[3, 8]под типомFilm).
По завершении итераций все данные объектов для всех типов будут загружены:
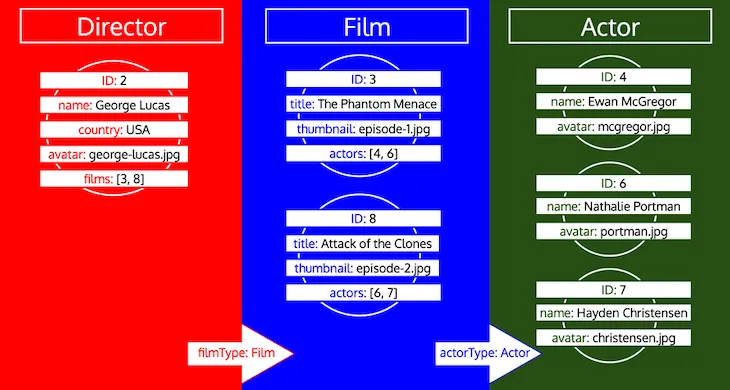
Обратите внимание, как собираются все ID для типа до того, как тип будет обработан в очереди. Если, например, добавить реляционное поле preferredActors к типу Director, эти ID будут добавлены в очередь под типом Actor и будут обработаны вместе с ID из поля actors типа Film:
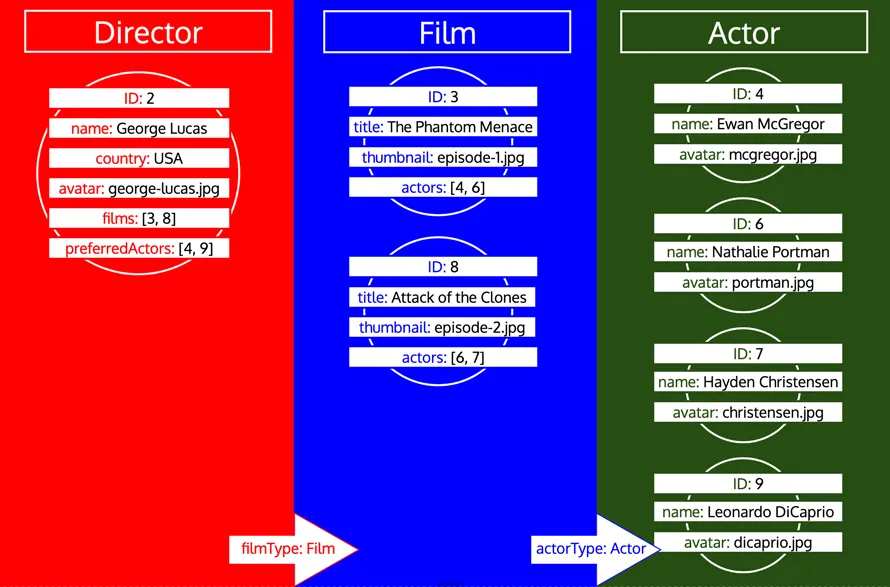
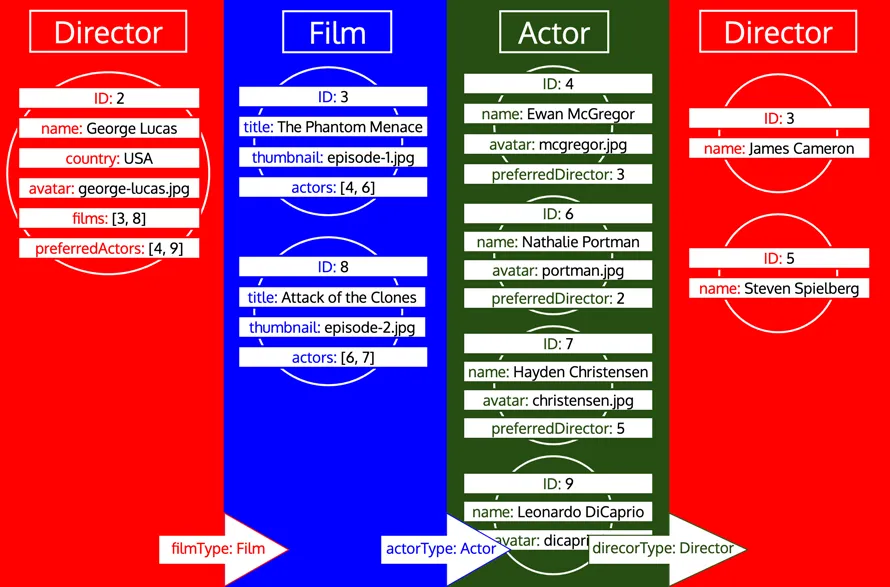
Однако если тип уже был обработан, а затем нам нужно загрузить больше данных этого типа, это будет новой итерацией по этому типу. Например, добавление реляционного поля preferredDirector к типу Author приведёт к тому, что тип Director будет снова добавлен в очередь:
Теперь, когда все данные объектов получены, необходимо придать им форму ожидаемого ответа, отражающую GraphQL-запрос. Однако, как видно, данные не имеют требуемой древовидной структуры. Вместо этого реляционные поля содержат ID вложенного объекта, эмулируя то, как данные представлены в реляционной базе данных. Следовательно, продолжая эту аналогию, данные, полученные для каждого типа, можно представить в виде таблицы:
Таблица для типа Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Таблица для типа Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Таблица для типа Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Имея все данные, организованные в виде таблиц, и зная, как каждый тип связан с остальными (то есть Director ссылается на Film через поле films, Film ссылается на Actor через поле actors), GraphQL-сервер может легко преобразовать данные в ожидаемую древовидную форму:
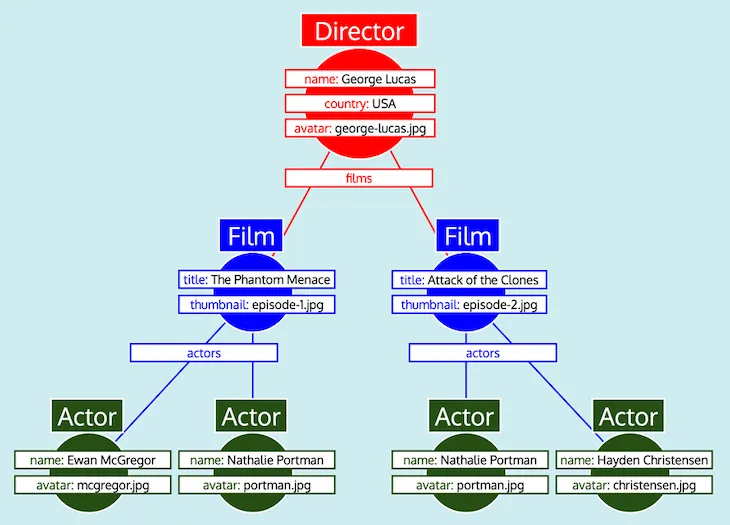
Наконец, GraphQL-сервер выводит дерево, которое имеет форму ожидаемого ответа:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Анализ временной сложности решения
Проанализируем нотацию «большое O» алгоритма загрузки данных, чтобы понять, как растёт количество запросов к базе данных по мере увеличения числа входных данных, и убедиться, что данное решение является производительным.
Движок загрузки данных загружает данные в итерациях, соответствующих каждому типу. К моменту начала итерации у него уже будет список всех ID всех объектов для получения, поэтому он может выполнить один запрос для получения всех данных соответствующих объектов. Отсюда следует, что количество запросов к базе данных будет расти линейно с числом типов, задействованных в запросе. Иными словами, временная сложность составляет O(n), где n — количество типов в запросе (однако если тип итерируется более одного раза, он должен быть добавлен к n более одного раза).
Это решение очень производительно — значительно лучше экспоненциальной сложности, ожидаемой при работе с графами, или логарифмической сложности при работе с деревьями.
Реализованный PHP-код
Процесс загрузки данных происходит в функции getComponentData класса Engine из пакета Component Model.