
Управление порядком разрешения полей
Цель директивы @export, предоставляемой Multiple Query Execution, — экспортировать значение поля (или набора полей) в переменную, чтобы использовать её в другом месте запроса.
Эта директива не работала бы, если бы чтение переменной происходило до экспорта значения в неё. Поэтому движку необходим способ контролировать порядок выполнения полей.
Gato GraphQL предоставляет возможность управлять порядком выполнения полей через сам запрос. Движок загружает данные итерационно для каждого типа: сначала разрешая все поля первого встреченного в запросе типа, затем все поля второго, и так далее, пока не останется типов для обработки.
Например, следующий запрос, включающий объекты типов Director, Film и Actor:
{
directors {
name
films {
title
actors {
name
}
}
}
}...разрешается движком GraphQL в таком порядке:

Если после обработки тип снова встречается в запросе для получения незагруженных данных (например, из дополнительных объектов или дополнительных полей уже загруженных объектов), то тип добавляется в конец списка итераций повторно.
Например, если мы также запрашиваем поле preferredDirector у Actor (которое возвращает объект типа Director) вот так:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...то движок GraphQL обрабатывает запрос в следующем порядке:

Посмотрим, как это проявляется при выполнении @export в одном запросе. В первой попытке мы создаём запрос так, как делали бы обычно, не задумываясь о порядке выполнения полей:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}При выполнении запроса получаем такой ответ:
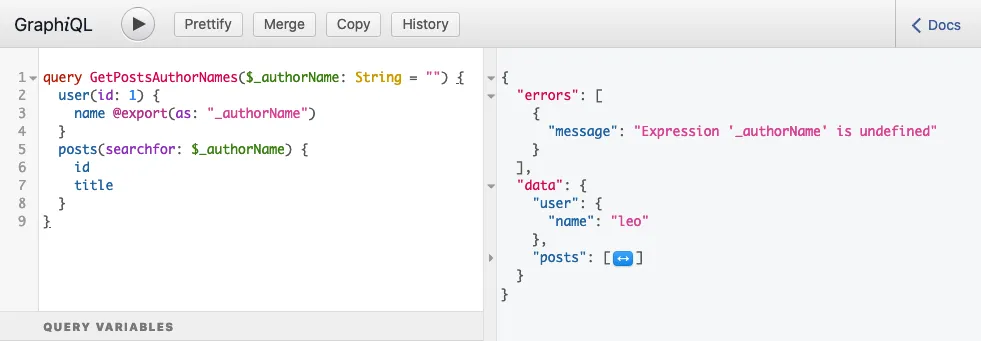
...содержащий следующую ошибку:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}Эта ошибка означает, что в момент чтения переменной $authorName она ещё не была установлена — её значение было undefined.
Разберёмся, почему это происходит. Сначала проанализируем, какие типы встречаются в запросе (добавлены в виде комментариев ниже):
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}Для обработки типов и загрузки их данных движок загрузки данных добавляет корневой тип запроса Root в список FIFO (First-In, First-Out — «первым вошёл, первым вышел»), делая [Root] начальным списком, передаваемым алгоритму, а затем последовательно итерирует по типам:
| # | Операция | Список |
|---|---|---|
| 0 | Подготовить список FIFO | [Root] |
| 1a | Извлечь первый тип из списка (Root) | [] |
| 1b | Обработать все поля, запрошенные из типа Root:→ user(by: {id: 1})→ posts(filter: { search: $authorName })Добавить их типы ( User и Post) в список | [User, Post] |
| 2a | Извлечь первый тип из списка (User) | [Post] |
| 2b | Обработать поле, запрошенное из типа User:→ name @export(as: "authorName")Поскольку это скалярный тип ( String), добавлять его в список не нужно | [Post] |
| 3a | Извлечь первый тип из списка (Post) | [] |
| 3b | Обработать все поля, запрошенные из типа Post:→ id→ titleПоскольку это скалярные типы ( ID и String), добавлять их в список не нужно | [] |
| 4 | Список пуст, итерация завершается. |
Здесь видна проблема: @export выполняется на шаге 2b, но был прочитан на шаге 1b.
Именно здесь нам нужно управлять потоком выполнения полей. Реализованное решение заключается в откладывании момента чтения экспортированной переменной — достигается это путём искусственного запроса поля self из типа Root.
Поле self, как следует из его названия, возвращает тот же объект; применённое к объекту Root, оно возвращает тот же объект Root. Возможно, возникнет вопрос: «если корневой объект у меня уже есть, зачем его снова получать?». Дело в том, что алгоритм движка будет вынужден добавить эту новую ссылку на Root в конец списка FIFO, и мы можем намеренно распределять запрашиваемые поля до или после каждой из этих итераций.
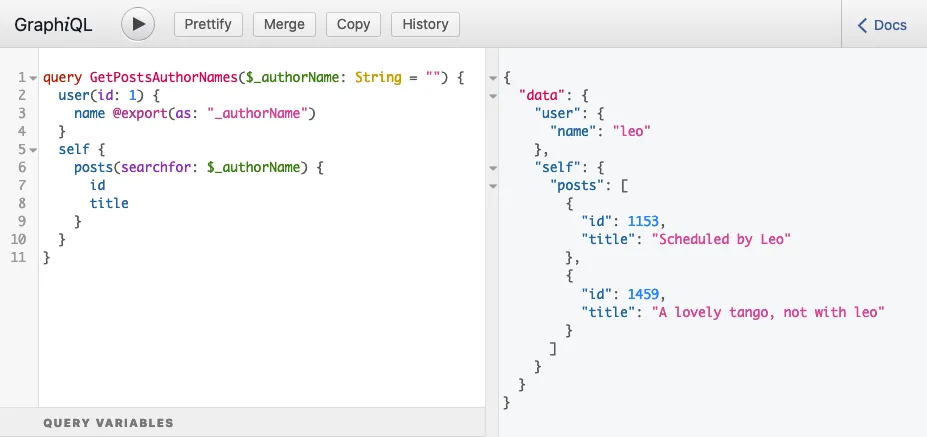
Вот почему поле posts(filter:{ search: $authorName }) помещается внутрь поля self в приведённом выше запросе, и выполнение запроса даёт ожидаемый ответ:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Рассмотрим порядок обработки типов для этого запроса, чтобы понять, почему он работает корректно:
| # | Операция | Список |
|---|---|---|
| 0 | Подготовить список FIFO | [Root] |
| 1a | Извлечь первый тип из списка (Root) | [] |
| 1b | Обработать все поля, запрошенные из типа Root:→ user(by: {id: 1})→ selfДобавить их типы ( User и Root) в список | [User, Root] |
| 2a | Извлечь первый тип из списка (User) | [Root] |
| 2b | Обработать поле, запрошенное из типа User:→ name @export(as: "authorName")Поскольку это скалярный тип ( String), добавлять его в список не нужно | [Root] |
| 3a | Извлечь первый тип из списка (Root) | [] |
| 3b | Обработать поле, запрошенное из типа Root:→ posts(filter:{ search: $authorName })Добавить его тип ( Post) в список | [Post] |
| 4a | Извлечь первый тип из списка (Post) | [] |
| 4b | Обработать все поля, запрошенные из типа Post:→ id→ titleПоскольку это скалярные типы ( ID и String), добавлять их в список не нужно | [] |
| 5 | Список пуст, итерация завершается. |
Теперь видно, что проблема решена: @export выполняется на шаге 2b, а читается на шаге 3b.
Multiple Query Execution делает именно это при разделении запросов: преобразует документ GraphQL, добавляя поля self, чтобы поля каждой операции выполнялись только после того, как будут разрешены все поля всех предыдущих операций.