
Конвейер директив
Директивы размещаются в конвейере и выполняются по порядку. Их исходная схема проста и выглядит так:

В этой архитектуре:
- Входными данными конвейера является значение поля, предоставленное резолвером поля
- Каждая директива выполняет свою логику и передаёт результат следующей директиве в конвейере
- Выходными данными конвейера будет разрешённое значение поля, обработанное всеми директивами
Однако эта архитектура не использует GraphQL в полной мере. Ниже описаны все этапы реального конвейера директив, вплоть до фактического дизайна, реализованного в Gato GraphQL.
Директивы как строительные блоки разрешения запроса
Изначально можно было бы рассмотреть вариант, при котором сервер GraphQL разрешает поле с помощью некоего механизма, а затем передаёт это значение в качестве входных данных в конвейер директив.
Однако гораздо проще иметь единый механизм для решения всех задач: вызов резолверов полей (как для проверки, так и для разрешения полей) уже можно выполнять через конвейер директив. В этом случае конвейер директив является единственным механизмом, используемым для разрешения запроса.
По этой причине сервер Gato GraphQL снабжён двумя специальными директивами:
@validateвызывает резолвер поля для проверки того, что поле может быть разрешено (например: синтаксис корректен, поле существует и т. д.)- В случае успеха
@resolveValueAndMergeвызывает резолвер поля для разрешения поля и объединяет значение с объектом ответа
Обе они относятся к специальному типу «системных» директив: они зарезервированы исключительно для движка GraphQL и неявно присутствуют в каждом поле. (Напротив, стандартные директивы являются явными: они добавляются пользователем в запрос.)
Используя эти две директивы, следующий запрос:
query {
field1
field2 @directiveA
}...будет разрешён как такой:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}Конвейер теперь выглядит следующим образом (обратите внимание, что конвейер получает поле в качестве входных данных, а не его первоначально разрешённое значение):

Слоты конвейера
Директивы обычно выполняются после @resolveValueAndMerge, поскольку они, скорее всего, предполагают обновление значения разрешённого поля. Однако существуют другие директивы, которые должны выполняться до @validate или между @validate и @resolveValueAndMerge.
Например:
- Для измерения времени, затраченного на разрешение поля, директива
@traceExecutionTimeможет получать текущее время до и после разрешения поля, помещая поддирективу@startTracingExecutionTimeв начало и@endTracingExecutionTimeв конец конвейера - Директива
@cacheдолжна проверить, кэшировано ли запрошенное поле, и вернуть этот ответ до выполнения@resolveValueAndMerge
Конвейер предоставляет пять различных слотов через класс PipelinePositions, и директива указывает, в каком из них она должна выполняться:
- Слот
"beginning": в самом начале - Слот
"before-validate": до выполнения проверки - Слот
"middle": после проверки и до разрешения поля - Слот
"after-resolve": после разрешения поля - Слот
"end": в самом конце
Конвейер директив теперь выглядит так (рассматриваем только 3 этапа для упрощения):

Обратите внимание, насколько легко директивы @skip и @include реализуются в этой архитектуре: находясь в слоте "middle", они могут указывать директиве @resolveValueAndMerge (а также всем директивам на более поздних этапах конвейера) не выполняться, устанавливая флаг skipExecution в true.
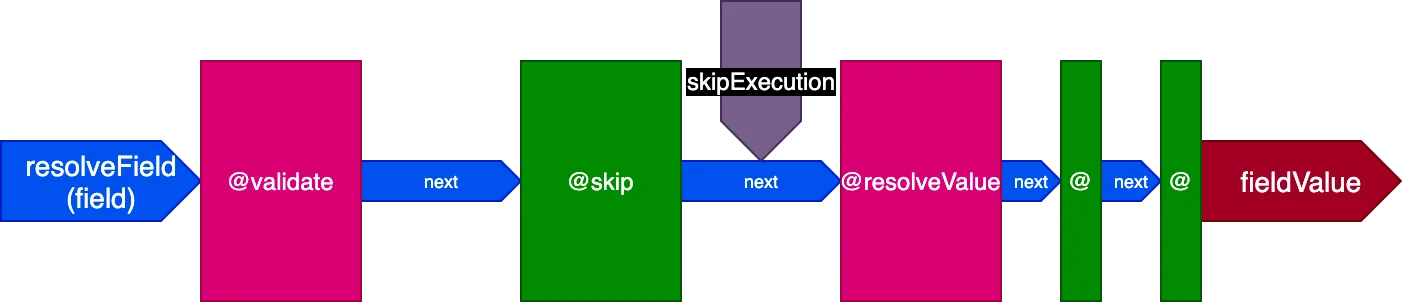
Выполнение директивы для нескольких полей за один вызов
До сих пор мы рассматривали одно поле в качестве входных данных для конвейера директив. Однако в типичном GraphQL-запросе мы получаем несколько полей, для которых нужно выполнять директивы.
Например, в запросе ниже директива @upperCase выполняется для полей "field1" и "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}Более того, поскольку движок GraphQL добавляет системные директивы @validate и @resolveValueAndMerge к каждому полю в запросе, так что следующий запрос:
query {
field1
field2
field3
}...разрешается как такой:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Тогда системные директивы всегда будут получать все поля в качестве входных данных.
Как следствие, конвейер директив спроектирован для получения нескольких полей в качестве входных данных, а не только одного за раз:

Эта архитектура более эффективна, поскольку выполнение директивы один раз для всех полей быстрее, чем выполнение её один раз для каждого поля, при этом результаты будут идентичными.
Например, при проверке, вошёл ли пользователь в систему для предоставления доступа к схеме, операция может быть выполнена только один раз. Выполнение следующего кода:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}эффективнее, чем выполнение такого кода:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Это может показаться незначительным при вызове локальной функции вроде isUserLoggedIn, однако это может существенно изменить ситуацию при взаимодействии с внешними сервисами, например при разрешении REST-эндпоинтов через GraphQL. В таких случаях однократное выполнение функции вместо многократного может решить, возможно ли вообще предоставить ту или иную функциональность.
Рассмотрим пример. При взаимодействии с Google Translate через директиву @translate GraphQL API должен установить сетевое соединение. Тогда выполнение этого кода будет максимально быстрым:
googleTranslateFields([$field1, $field2, $field3]);Напротив, выполнение функции по отдельности несколько раз приведёт к большей задержке, что увеличит время ответа и ухудшит производительность API. Возможно, для перевода 3 строк (где поле — это переводимая строка) разница невелика, но для 100 и более строк она определённо ощутима:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Кроме того, однократное выполнение функции со всеми входными данными может дать лучший результат, чем выполнение функции для каждого поля независимо. Снова используя Google Translate в качестве примера: перевод будет точнее, чем больше данных мы предоставим сервису.
Например, при выполнении кода ниже:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");При первом независимом выполнении Google не знает контекста для "fork", поэтому может вернуть «fork» как столовый прибор, как развилку дороги или с другим значением. Однако если вместо этого выполнить:
googleTranslate(["fork", "road", "sign"]);Из этого большего объёма информации Google может сделать вывод, что "fork" относится к развилке дороги, и вернуть точный перевод.
Именно по этим причинам директивы в конвейере получают все входные поля вместе, и затем каждая директива может сама решить, как лучше выполнить свою логику на этих входных данных (однократное выполнение для каждого входного данного, однократное выполнение, охватывающее все входные данные, или что-либо среднее).
Конвейер теперь выглядит так:
Выполнение единого конвейера директив для всего запроса
Только что мы убедились, что имеет смысл выполнять несколько полей для каждой директивы; однако это хорошо работает, пока все поля имеют одинаковые применённые директивы. Когда директивы различаются, это может привести к большей сложности, затрудняющей реализацию и снижающей часть полученных преимуществ.
Посмотрим, как это происходит. Рассмотрим следующий запрос:
query {
field1 @directiveA
field2
field3
}Эта директива эквивалентна такой:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}В этом сценарии поля field2 и field3 имеют одинаковый набор директив, а field1 — отличный, и нам пришлось бы создать 2 разных конвейера для разрешения запроса:
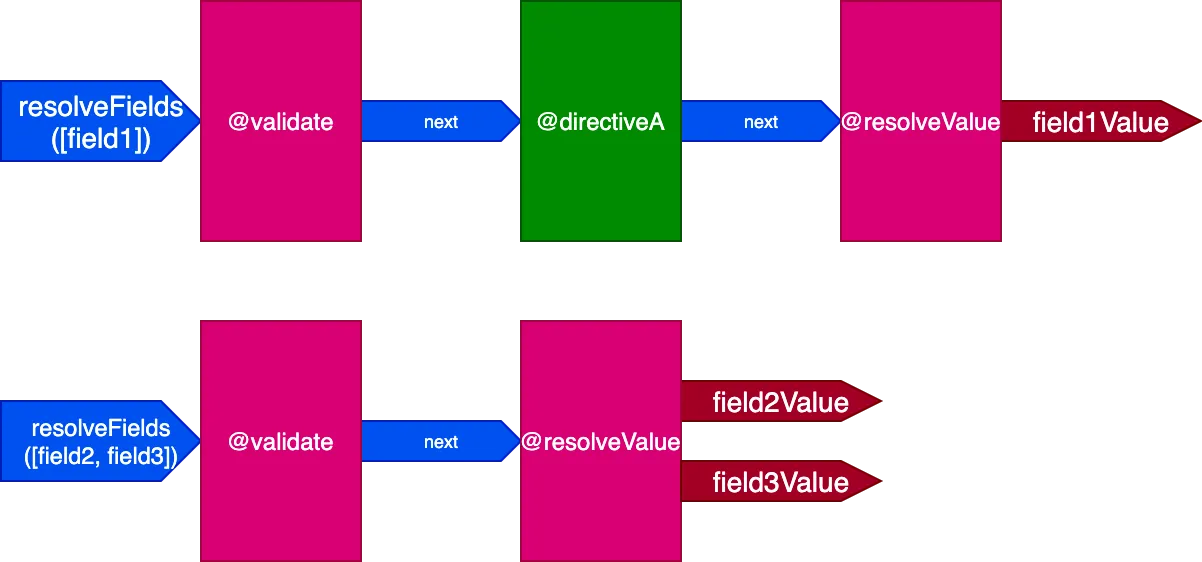
А когда все поля имеют уникальный набор директив, эффект более выражен. Рассмотрим этот запрос:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Что эквивалентно такому:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}В этой ситуации у нас будет 3 конвейера для обработки 3 полей, вот так:
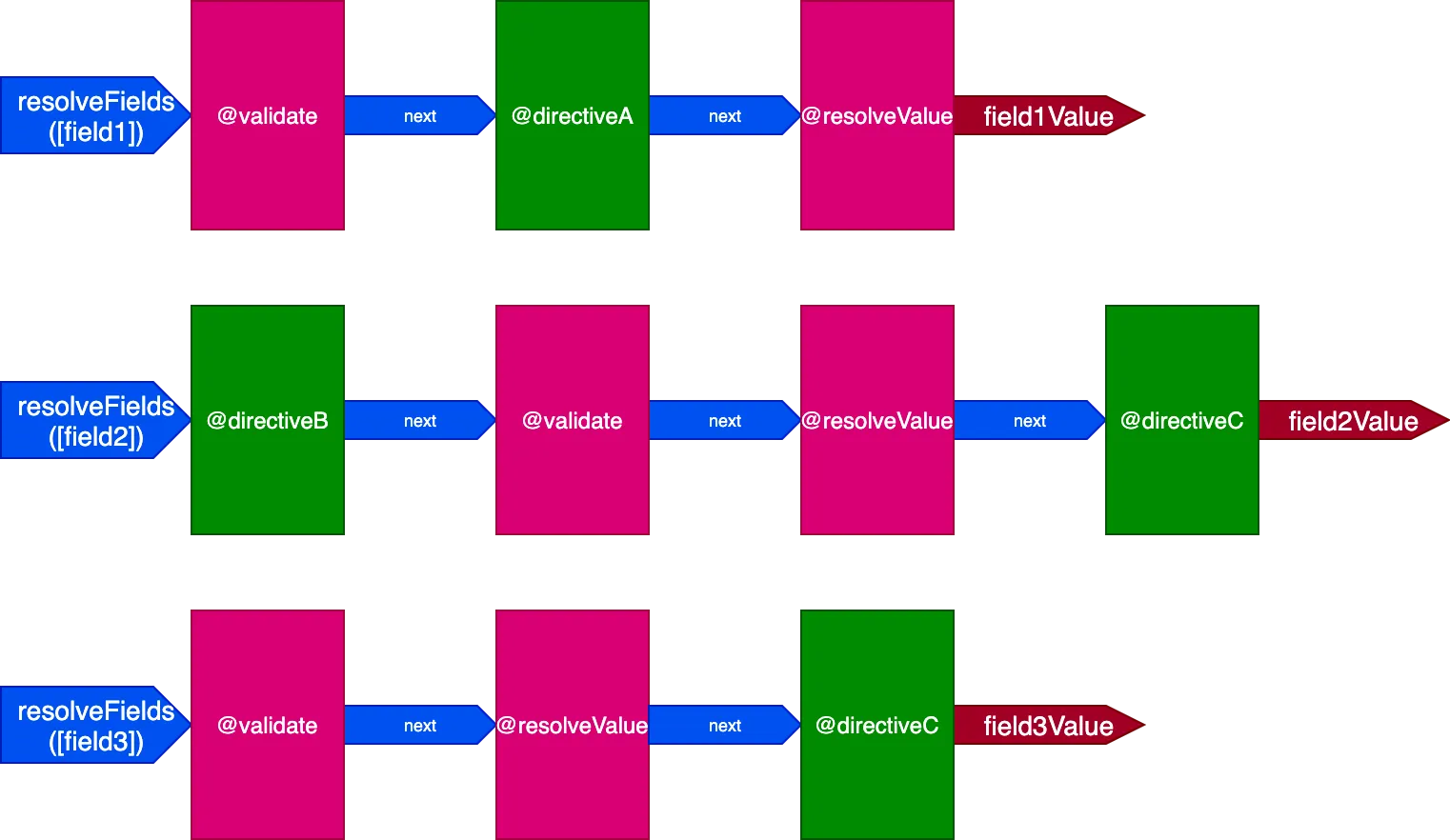
В этом случае, несмотря на то что директивы @validate и @resolveValueAndMerge применяются к 3 полям, поскольку они выполняются через 3 разных конвейера директив, они будут выполняться независимо друг от друга, что возвращает нас к ситуации, когда директива выполняется для одного элемента за раз.
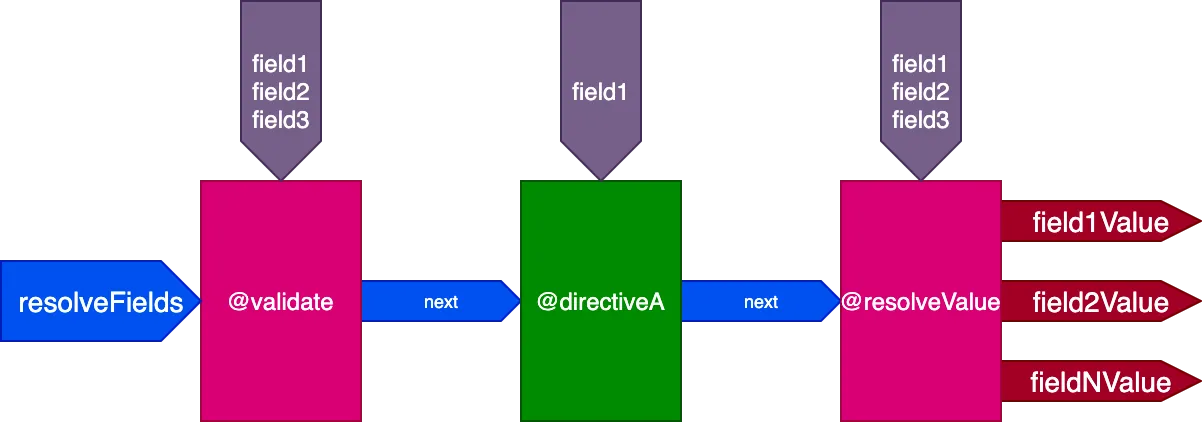
Решением этой проблемы является отказ от создания нескольких конвейеров и работа с единым конвейером для всех полей. Как следствие, движок больше не передаёт поля в качестве входных данных в конвейер, поскольку не все директивы одного конвейера будут взаимодействовать с одним и тем же набором полей; вместо этого каждая директива должна получать собственный список полей в качестве собственных входных данных.
Тогда для этого запроса:
query {
field1 @directiveA
field2
field3
}...директивы @validate и @resolveValueAndMerge получат все 3 поля в качестве входных данных, а directiveA получит только "field1":
А для этого запроса:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...директивы @validate и @resolveValueAndMerge получат все 3 поля в качестве входных данных, directiveA получит только "field1", directiveB получит только "field2", а directiveC получит "field2" и "field3":
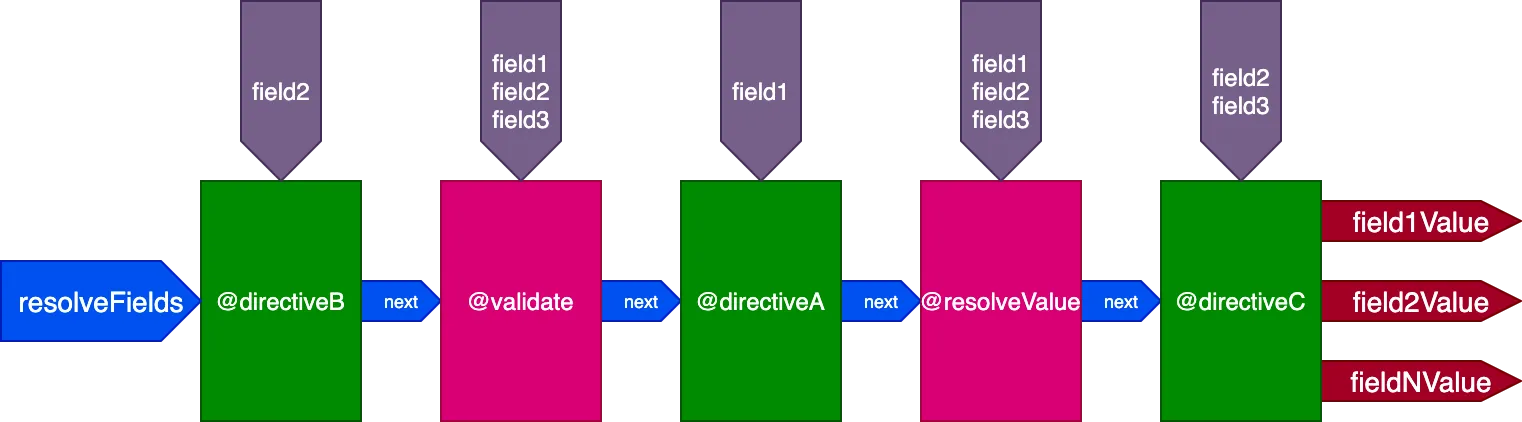
Управление выполнением директивы по идентификаторам
До сих пор директива на каком-либо этапе могла влиять на выполнение директив на более поздних этапах с помощью некоего флага skipExecution. Однако этот флаг недостаточно детален для всех случаев.
Например, рассмотрим директиву @cache, расположенную в слоте "end" для хранения значения поля, чтобы при следующем запросе поля его значение можно было получить из кэша с помощью директивы @getCache, расположенной в слоте "middle":
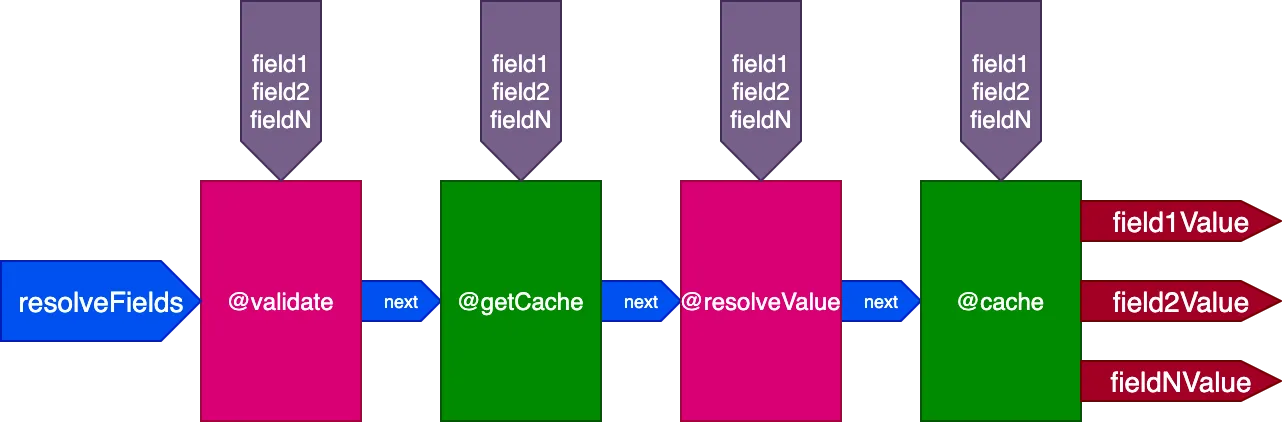
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Сервер получит и закэширует 2 записи. Затем выполним тот же запрос, но применительно к 4 записям:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}При выполнении этого 2-го запроса 2 записи из 1-го запроса уже были закэшированы, а остальные 2 — нет. Однако нам потребовалось бы, чтобы все 4 записи уже были в кэше для использования флага skipExecution. Было бы лучше, если бы мы могли получить первые 2 записи из кэша и разрешить только 2 другие записи.
Поэтому мы обновляем дизайн конвейера. Отказываемся от флага skipExecution и вместо этого передаём каждой директиве список идентификаторов объектов для каждого поля, к которому должна применяться директива, через входной объект fieldIDs:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}Переменная fieldIDs уникальна для каждой директивы, и каждая директива может изменять экземпляр fieldIDs для всех директив на более поздних этапах. Тогда skipExecution можно выполнять гранулярно, идентификатор за идентификатором, просто удаляя идентификатор из fieldIDs для всех последующих директив в стеке.
Конвейер теперь выглядит так:
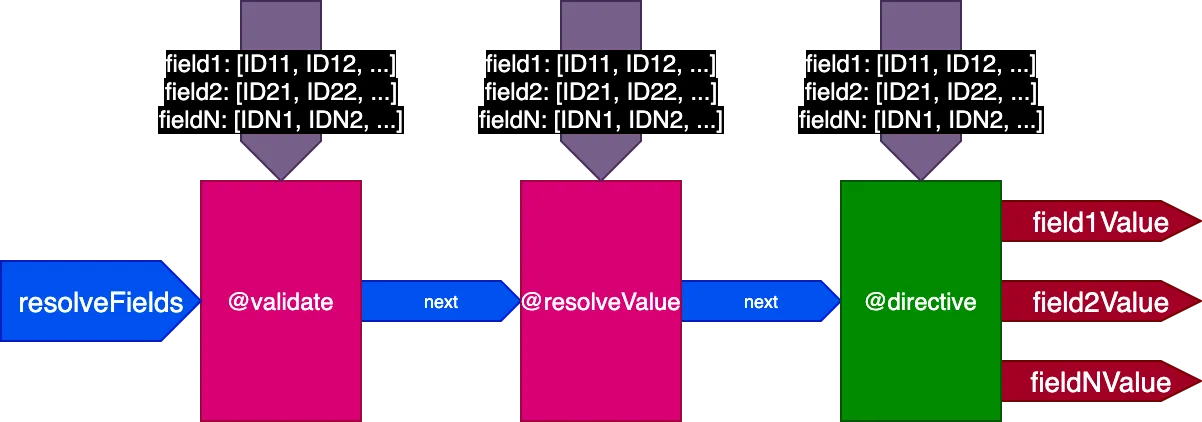
Применительно к предыдущему примеру: при выполнении первого запроса с переводом 2 записей конвейер выглядит так:
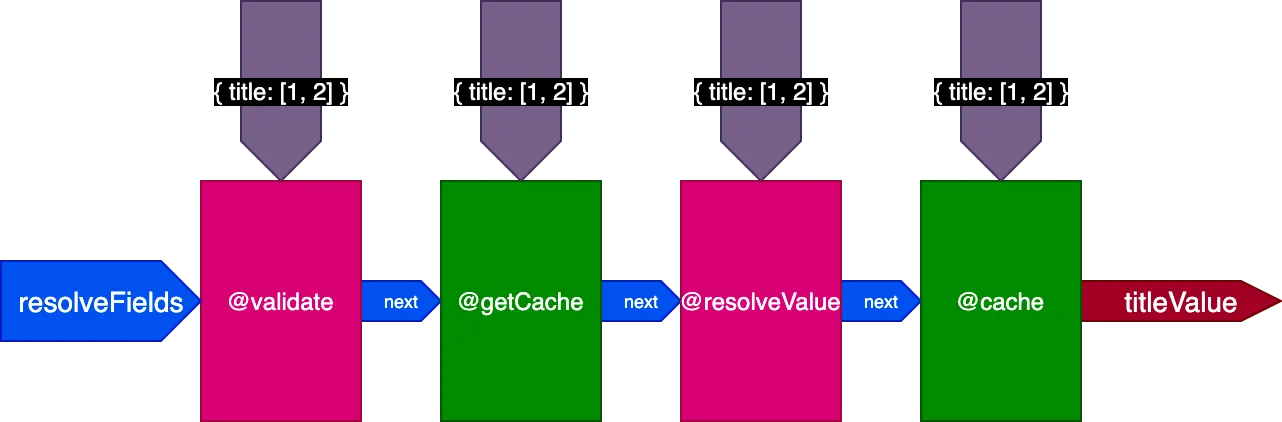
При выполнении второго запроса с переводом 4 записей директива @getCache получает идентификаторы всех 4 записей, но и @resolveValueAndMerge, и @cache получат только идентификаторы последних 2 записей (которые не закэшированы):
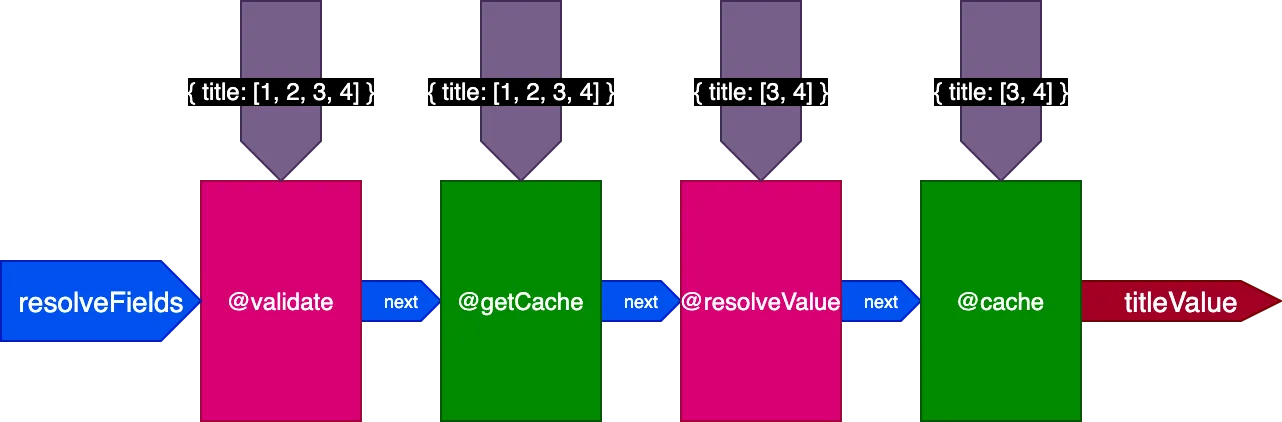
Итоговая картина
Это окончательный дизайн конвейера директив:
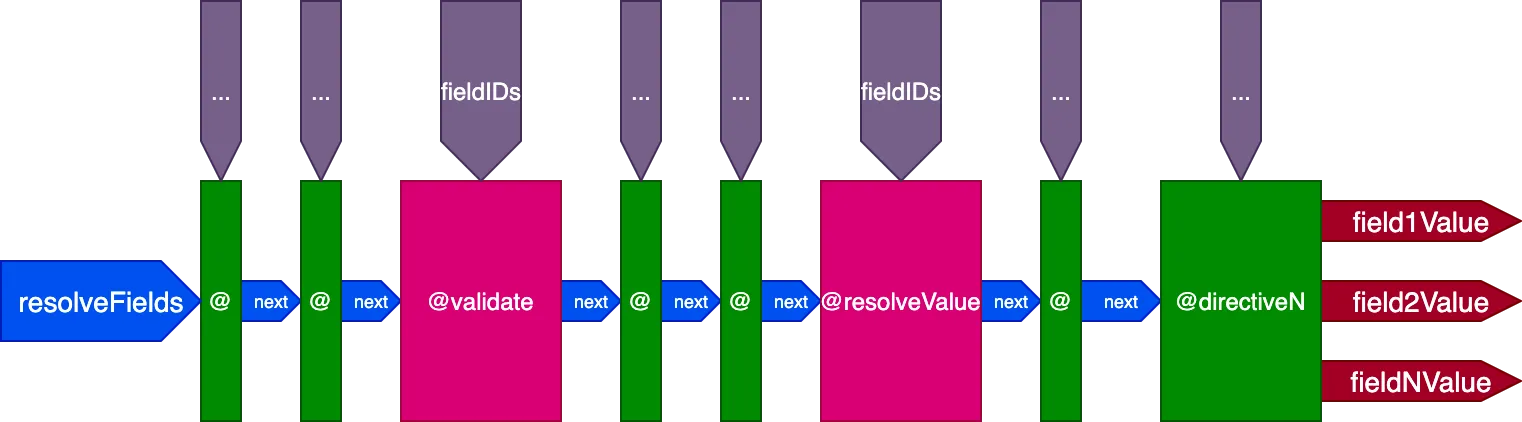
Подводя итог, вот его характеристики:
- Резолверы полей вызываются изнутри конвейера директив через директивы
@validateи@resolveValueAndMerge - Директивы могут быть размещены в любом из 5 слотов:
"beginning","before-validate","middle","after-validate"и"end" - Директивы разрешают несколько полей за один вызов
- Единый конвейер содержит все директивы, задействованные в запросе
- Каждая директива получает собственный набор идентификаторов для разрешения по каждому полю через переменную
fieldIDs - Директивы могут изменять переменную
fieldIDsдля всех директив на более позднем этапе конвейера